Overview: LLM-Planner continuously updates the high-level plans based on the feedback from the environment.
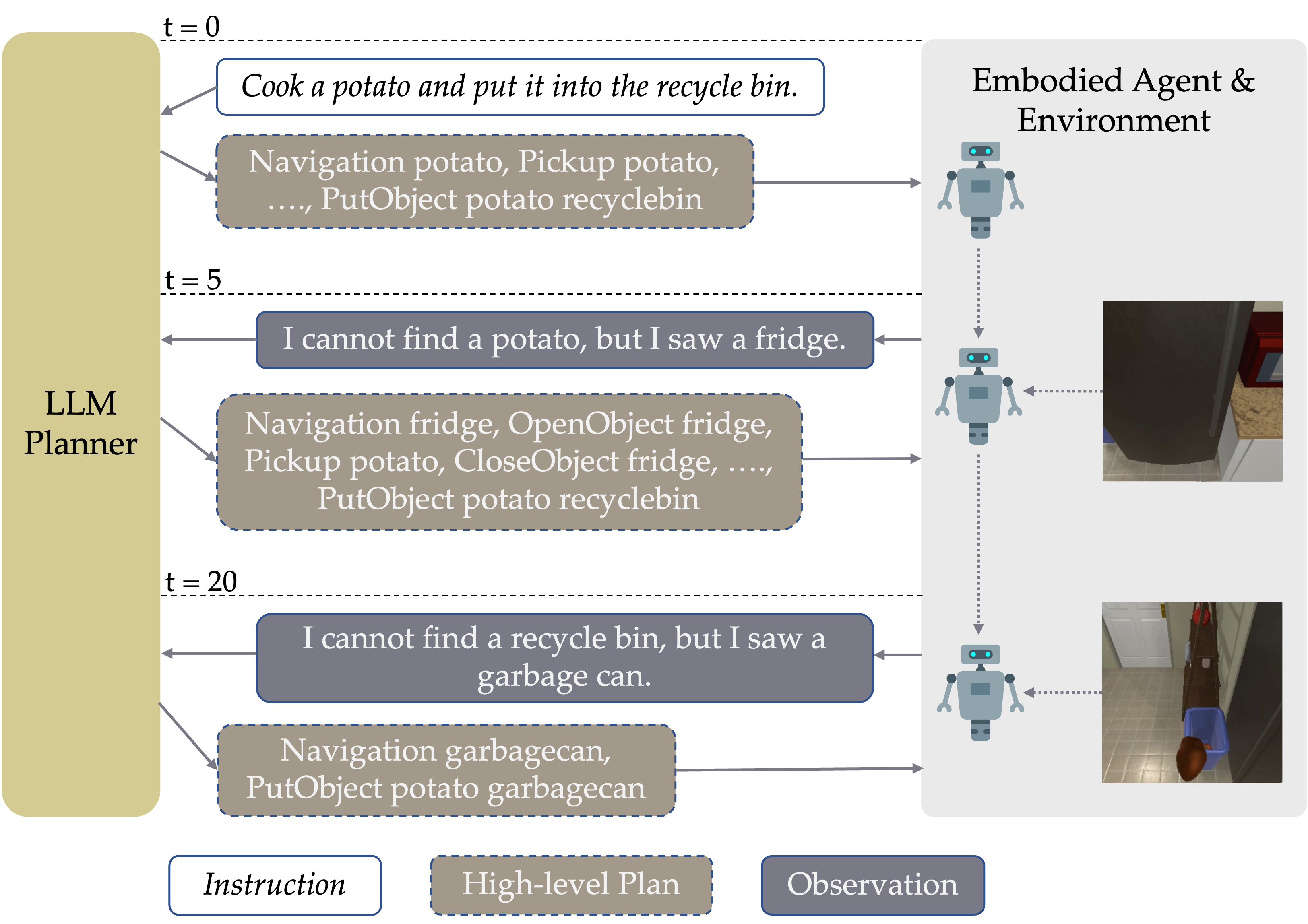
Overview: LLM-Planner continuously updates the high-level plans based on the feedback from the environment.
This study focuses on using large language models (LLMs) as a planner for embodied agents that can follow natural language instructions to complete complex tasks in a visually-perceived environment. The high data cost and poor sample efficiency of existing methods hinders the development of versatile agents that are capable of many tasks and can learn new tasks quickly.
In this work, we propose a novel method, LLM-Planner, that harnesses the power of large language models to do few-shot planning for embodied agents. We further propose a simple but effective way to enhance LLMs with physical grounding to generate and update plans that are grounded in the current environment.
Experiments on the ALFRED dataset show that our method can achieve very competitive few-shot performance: Despite using less than 0.5% of paired training data, LLM-Planner achieves competitive performance with recent baselines that are trained using the full training data. Existing methods can barely complete any task successfully under the same few-shot setting. Our work opens the door for developing versatile and sample-efficient embodied agents that can quickly learn many tasks.
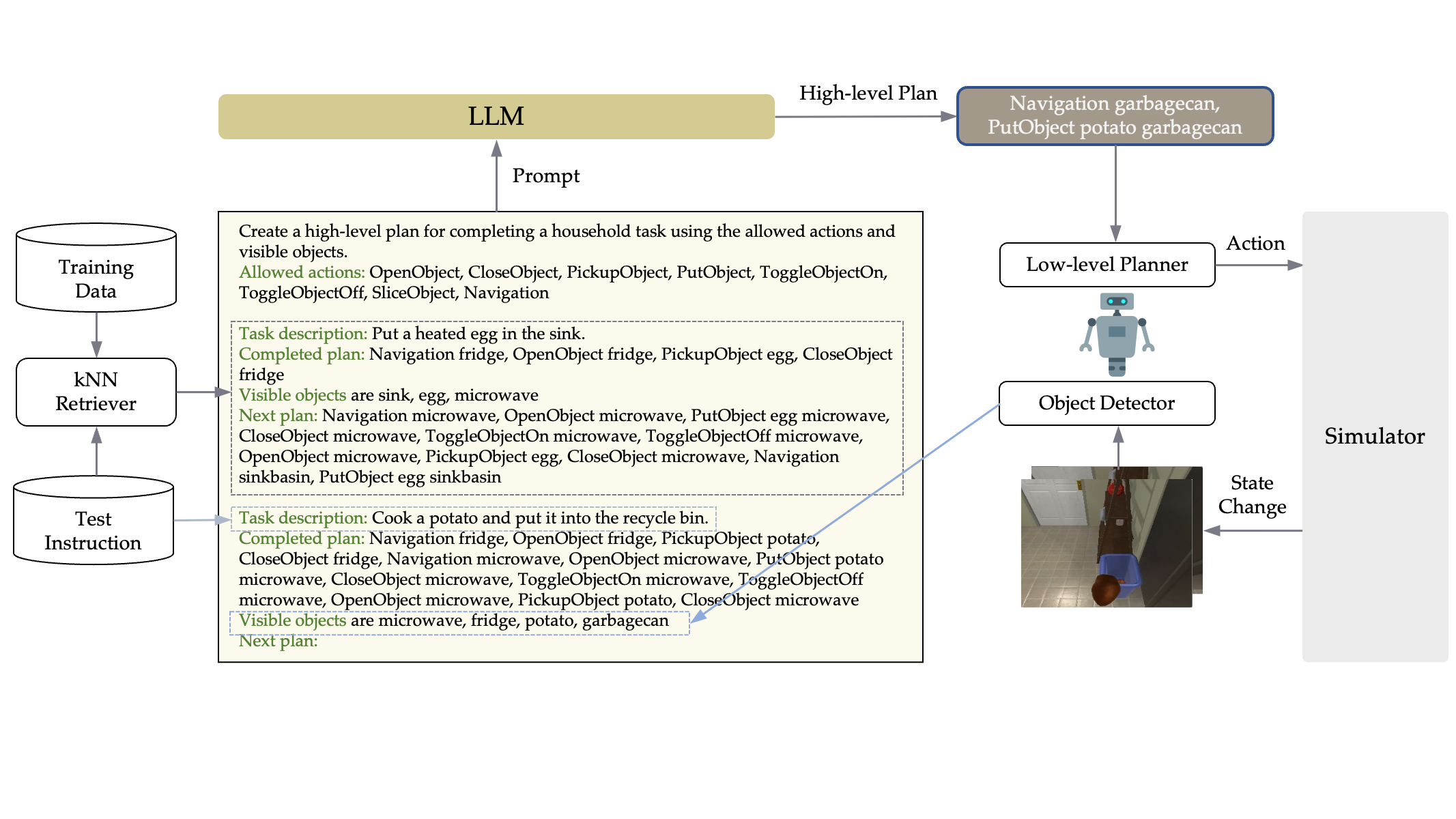
The prompt includes an explanation of the task, a list of possible high-level actions, 9 in-context examples selected by the kNN retriever from 100 training examples, and a current test example. For dynamic grounded re-planning, we add the subgoals that have been completed and the list of objects observed in the environment.
We only use 100 pairs of trajectory-instruction training data to retrieve in-context examples and to tune all the hyperparamters. Therefore, our work is under the true few-shot setting.
HLP ACC is the percentage of the correct prediction of HLP compared to the ground-truth of HLP for all episode. Only if a prediction of HLP in an episode exactly matches the ground-truth, we consider the prediction as a correct one. For the definition of SR, please refer to ALFRED.
We integrated LLM-Planner with HLSM and evaluated its performance on ALFRED dataset. Despite using less than 0.5% of paired training data, LLM-Planner achieved competitive performance compared to models trained on full data and even outperformed multiple other baselines that were trained using the full data.
| Training Data | Instruction | Model | Test Unseen | Valid Unseen | |
|---|---|---|---|---|---|
| SR | SR | HLP ACC | |||
| Full-data | Goal-only | HLSM | 20.27 | 18.28 | 31.24 – 70.17 |
| Step-by-step | E.T. | 8.57 | 7.32 | -- | |
| M-TRACK | 16.29 | 17.29 | -- | ||
| FILM | 27.80 | -- | 54.93 | ||
| LEBP | 28.30 | -- | -- | ||
| Few-shot | Goal-only | LLM-Planner (Static) | 11.58 | 11.10 | 28.67 |
| LLM-Planner | 13.41 | 12.92 | 33.81 – 55.85 | ||
| Step-by-step | HLSM | 0.61 | 0.00 | 0.00 | |
| FILM | 0.20 | 0.00 | 0.00 | ||
| LLM-Planner (Static) | 15.83 | 14.26 | 43.24 | ||
| LLM-Planner | 16.42 | 15.36 | 46.59 – 68.31 | ||
@InProceedings{song2023llmplanner,
author = {Song, Chan Hee and Wu, Jiaman and Washington, Clayton and Sadler, Brian M. and Chao, Wei-Lun and Su, Yu},
title = {LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
}